

AI-modeller som lärt sig skriva egna texter genom så kallad maskininlärning har slagit världen med häpnad senaste åren. Redan när GPT-3 kom för två år sen fick den skriva debattartiklar som publicerades i flera stora tidningar. Och för några veckor sedan släpptes dess systermodell ChatGPT, som är ännu bättre på att att konversera som en människa. Bloomberg pratar om “AI:s iPhone-ögonblick” och techanalytikern Benedict Evans menar att det här är lika stort som när maskininlärning slog igenom för tio år sen. Så för dig som inte testat ChatGPT: sluta läsa och gör det först!
Det var dock inte länge sedan de här modellerna var ganska usla. Så vilka tekniska revolutioner låg bakom att man helt plötsligt lyckades skapa en modell som skrev som en människa? Inga. Modellerna är framförallt bara större: de består av fler vikter, där varje vikt kan ses som ett samband som modellen har lärt sig. GPT-2 innehöll 10x vikter jämfört med GPT(-1), och GPT-3 innehåller ytterligare mer än 10x. Och det var (nästan) hela skillnaden mellan en glorifierad copy-paste-generator och en modell som skrev text som en människa. Man kan förstås diskutera länge vad intelligens är, men det är svårt att förneka att de senaste modellerna “verkar” intelligenta på många sätt. De kan förstås inte lösa alla problem som en människa kan, men de kan å andra sidan diskutera massa saker mycket djupare än många människor.
I somras skrev jag om ifall maskiner kommer att bli smartare än människor. Idag tänkte jag zooma in på en viktig delfrågeställning: hur ser vägen dit ut? Kommer dagens sätt att jobba med maskininlärning — så kallad djupinlärning (deep learning) — ta oss hela vägen fram till en artificiell generell intelligens (AGI) som kan lösa olika typer av problem lika väl som en människa?
Två metoder för att uppnå artificiell intelligens
Grovt räknat har det sedan datorernas barndom funnit två metoder för hur maskiner ska bli intelligenta:
låt människor strukturera all kunskap åt dem, eller
låt dem lära sig själva, dvs maskininlärning (machine learning, “ML”)
Alla pratar om Metod 2 idag — maskininlärning — men under många årtionden trodde man på Metod 1: att artificiell intelligens istället skulle baseras på stora kunskapsdatabaser. Här strukturerades inte bara mänsklig kunskap, utan även hur informationen hängde ihop med formella regler. Cyc är kanske det största sådana projektet, där mer än 1000 manår investerats sedan mitten på 80-talet. Det innehåller miljoner termer och tiotals miljoner regler, av typen:
(#$isa #$BillClinton #$UnitedStatesPresident)
(#$capitalCity #$France #$Paris)Dess skapare trodde att man på det här sättet kunde utrusta maskiner med slutledningsförmåga och “sunt förnuft”. Men den här typen av gigantiska, manuellt kurerade databaser slog aldrig igenom.
Snarare växte det fram tekniker där maskiner på egen hand kunde börja lära sig samband själva, utan att någon människa berättar för dem. Ett sätt att bygga system där maskiner kunde lära sig själva var att försöka modellera det utifrån den mänskliga hjärnan. Så redan på 1960-talet började teorier om “artificiella neurala nätverk” växa fram, löst baserat på hur syncentrum arbetar:
… and the overall architecture is reminiscent of the LGN–V1–V2–V4–IT hierarchy in the visual cortex ventral pathway. When ConvNet models and monkeys are shown the same picture, the activations of high-level units in the ConvNet explains half of the variance of random sets of 160 neurons in the monkey’s inferotemporal cortex.
På samma sätt som i hjärnans biologi (“cells that fire together, wire together“) kan träning leda till att vissa kopplingar mellan neuroner blir starkare än andra, och få då en högre vikt. Men fram till 2010-talets början var det här en nischföreteelse som få forskare trodde på.
Men år 2012 hade både datorkraft och algoritmer utvecklats, och nästan över en natt slog neurala nätverk igenom. Fokus hamnade på en approach som kom att kollas djupinlärning, där man hade flera lager efter varandra som successivt ger mening åt indatan. Hierarkin gör att datorn kan förstå mer komplicerade koncept (“ett ansikte”) i termer av enklare koncept (“ett öga”).
Hur jobbar vi med Metod 2 idag?
Så det visade sig snabbt att djupinlärning var oslagbart på att analysera bilder: dels för resultaten blev bättre, men också för att det var mycket lättare att sätta upp modellerna. De lärde sig själva vilka egenskaper som utmärkte all träningsdata, utan att människor manuellt behövde kartlägga det. Sen dess har djupinlärning blivit standard för att analysera bilder, och steg för steg tagit över andra användningsområden, till exempel att läsa och skapa text och bilder. Och nu händer används djupinlärning för nästan allt spännande inom ML-fältet, från att avkoda proteinstrukturer till styra bilar eller spela go.
Vi pratade om ML i Stedman Summaries #54, men här kommer en kort repetition: det handlar om att hitta statistiska samband i stora mängder träningsdata. Istället för att försöka förstå och beskriva mönster i indatan så testar man med att sätta upp ett antal samband, initialt nästan slumpmässigt. I vägledd (supervised) träning får modellen se massa exempel på sammanhängande indata (t ex en bild) och önskad utdata (t ex en “sanning” att bilden föreställer en katt). Och i slutändan väljer man de samband som bäst fångar relationen mellan indata och utdata i träningsdatat.
Sambanden i dagens ML-modeller utgörs av vikterna på olika kopplingar — vilka kopplingar mellan noder är viktigast? Vikterna kallas också parametrar, och de representerar ett sätt att omvandla indata för att komma till önskad utdata. Oftast förstår man inte varför parametrarna blir som de blir. Man kan bara konstatera att vissa parametrar lyckas förutspå utdata med en god precision, givet viss indata. Men tittar man på enskilda parametrar kan man följa hur de tränas, inte minst i problem som handlar om att känna igen bilder. Vissa parametrar i tidiga lager ger till exempel utslag för kanter i en bild. En annan parametrar i ett senare lager kan säga att modellen känner igen ett öga, och i ett ännu senare lager framträder ett ansikte.

Kommer Metod 2 att ta oss i mål?
Så tillbaka till dagens fråga: kan Metod 2 (djupinlärning) ta oss hela vägen till mänsklig intelligens? Räcker det att skala upp indata och antal parametrar, och så löser sig resten av sig själv? Eller kommer Metod 1 — strukturerad kunskap om olika symboler och regler — att slå tillbaka?
Det finns en intressant parallell till diskussionen inom utvecklingspsykologi och lingvistik om “tabula rasa”, den “tomma tavlan”. I årtusenden har filosofer, från Aristoteles till John Locke, diskuterat om en nyfödd människa redan är predisponerad att bete sig på ett visst sätt, eller om alla är tomma tavlor som formas av sina erfarenheter. Inom lingvistiken blev det en stor snackis på 60-talet när Noam Chomsky hävdade att hjärnan inte är en tom tavla, utan hårdkodad för att behandla just talat språk. Det finns ingen konsensus om den “universella grammatik” han förfäktat verkligen existerar, men däremot verkar det etablerat att det finns vissa strukturer i hjärnan som är anpassade för särskilda syften. Kan en dator gå från en tom tavla till generell intelligens med generiska ML-modeller som kan tränas på vad som helst, eller blir det bättre resultat om man utgår från vissa koncept och regler?
Hinton, “maskininlärningens gudfader”, som ledde det labb i Toronto som populariserade djupinlärning 2012, är övertygad om att djupinlärning är svaret. Med tillräckligt många parametrar kan modellerna strukturera tankar och resonera:
Hinton said that the idea that language can be deconstructed with almost mathematical precision is surprising, but true. “If you take the vector for Paris and subtract the vector for France and add Italy, you get Rome,” he said. “It’s quite remarkable.”
AI-forskaren Paul Christiano är inne på samma spår:
It now seems possible that we could build “prosaic” AGI, which can replicate human behavior but doesn’t involve qualitatively new ideas about “how intelligence works:”
It’s plausible that a large neural network can replicate “fast” human cognition, and that by coupling it to simple computational mechanisms — short and long-term memory, attention, etc. — we could obtain a human-level computational architecture.
För att tro på detta så tror man nog att stora mängder generiska neuroner lär sig på konceptuellt liknande sätt i en biologisk hjärna som i en artificiell model:
It would make sense to me if poorly-differentiated blobs of neurons, when having lots of problems thrown at them, gradually move from developing simpler pattern-recognition programs (eg edge detectors), to more complicated pattern-recognition programs, all the way up to world-modeling, without any of these being hard-coded into the territory.
Den intresserade allmänheten verkar hålla med: 89% av de som slagit vad i frågan på sajten Metaculus tror att vägen till generell intelligens kommer att bygga på djupinlärning.
Metod 2-laget har onekligen fått vatten på sin kvarn senaste åren: om och om igen har det hävdats att mer skala inte skulle lösa problem, och om och om igen har det visat sig att det varit just så enkelt. Bloggaren Scott Alexander raljerar lite över hur det brukar se ut:
Someone releases a new AI and demonstrates it doing various amazing things.
Somebody else (usually Gary Marcus) demonstrates that the AI also fails terribly at certain trivial tasks. This person argues that this shows that those tasks require true intelligence, whereas the AI is just clever pattern-matching.
A few months or years later, someone makes a bigger clever pattern-matcher, which does the tasks that supposedly require true intelligence just fine.
The it’s-not-true-intelligence objectors find other, slightly less trivial tasks that the new bigger AI still fails horribly at, then argue that surely these are the tasks that require true intelligence and that mere clever pattern-matchers will never complete.
Rinse and repeat.
Majoriteten av de konkreta problem som professor Gary Marcus hittade med GPT-2 vara mycket riktigt lösta med GPT-3. Men modellerna förbättras inte bara mellan nya officiella versioner snabbt, utan ibland bara på några veckor. Till exempel tog Marcus för några veckor sedan det här som exempel på hur lätt det är att lura AI-modeller som ChatGPT:
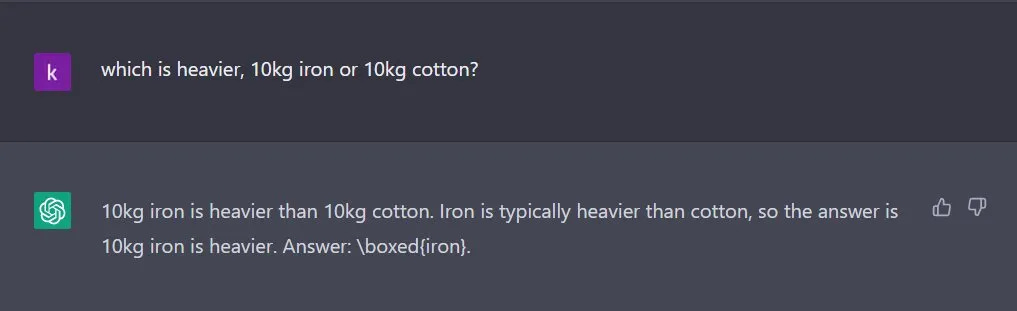
Nu när jag testade härom dan så hade ChatGPT förbättrats och gjorde inte det misstaget. (Och till skillnad från hur krångligt det skulle vara att uppdatera 8 miljarder människor så kunde förändringen bara göras på ett ställe, och så fick alla del av den!)

Så givet maskininlärnings snabba förbättringar månad för månad de senaste åren så verkar många numera tro att det räcker att skala dagens modeller:
The scaling hypothesis regards the blessings of scale as the secret of AGI: intelligence is ‘just’ simple neural units & learning algorithms applied to diverse experiences at a (currently) unreachable scale. As increasing computational resources permit running such algorithms at the necessary scale, the neural networks will get ever more intelligent.
Man pratar alltså som “uppskalningslagar”: hur mycket bättre blir en AI-modell om man ökar mängden indata och antalet parametrar? (Givet en begränsad beräkningskapacitet måste man välja mellan att läsa mer data eller ha fler parametrar som fångar mönster i datan. Ett tag trodde man att fler parametrar var viktigare än mer indata, men nya rön pekar på både kanske är lika viktiga.)
Det kan tyckas orimligt att statistiska modeller som beskriver indata och utdata kan leda till någon slags intelligens, men uppenbarligen funkar det (om än inte på mänsklig nivå än!). Maskininlärning är lite som kvantmekanik: det är inte så intuitivt, och det är svårt att säga hur det funkar, men det verkar rent empiriskt funka. Som jag skrev i Stedman Summaries #54:
Well, små steg på mikronivå har makrokonsekvenser. Tusentals myror kan bygga enorma myrstackar även om varje enskild myra är liten och ointelligent, allt du kan göra med en dator kan uttryckas med logiska grindar som genererar antingen en nolla eller en etta, och människans DNA kan beskrivs med kombinationer av fyra kvävebaser. På samma sätt kan vi se att maskininlärningsmodeller beter sig som om de vore intelligenta, även om de på mikronivå bara består av en stor uppsättning optimerade vikter.
Vissa forskare hävdar att människans unika minne för komplexa sekvenser har legat till grunden inte bara för aerobics, utan också dialog, planering, grammatik, resonemang och kanske till och med medvetande. Eftersom stora språkmodeller, som GPT-3, är specialiserade på just sekvensinlärning, är det rimligt att anta de har goda förutsättning för många av dessa olika färdigheter?
Forskarna inom kaosteori brukar prata om begreppet “emergens”. Åska kan till exempel förstås i termer av emergens, “eftersom den uppstår som en följd av de komplexa mönster och system som skapas av atmosfären, och inte kan förklaras av de enskilda atmosfäriska faktorerna i sig” (Ja, förklaringen kommer från ChatGPT. Snart skriver den kanske hela nyhetsbrevet..). Ett annat exempel är att film upplevs som mycket mer än de tusentals stillbilder som utgör filmen:
Technically, a movie is nothing but a stack of still images. Still, something special happens when these images are run through quickly enough to lose their individual quality and turn into continuous, lifelike motion (the effect known in psychology as “persistence of vision”).
På samma sätt kan en ML-modell få egenskaper som är svårt att förstå genom att bara titta på deras beståndsdelar. Men räcker det hela vägen till mänsklig intelligens?
Kommer Metod 1 att slå tillbaka?
Det finns också många som tror att åtminstone inslag av Metod 1 måste till om vi nånsin ska nå generell intelligens. Dessa skeptiker erkänner att GPT-3, DALL-E etc utgör fantastiska framsteg över sina föregångare. Men de menar att man kommer att slå pannan i en vägg snart om man inte ändrar metod, oavsett hur mycket man försöker skala modellen.
Man pekar på att dagens modeller bara är en slags “stokastiska papegojor” som lärt sig samband utifrån, och inte har en modell över hur världen funkar. Det vet egentligen inget om Julias Caesar eller romarriket. De vet bara att det är ord som ofta brukar diskuteras tillsammans. Så kanske funkar djupinlärning för det som Kahneman kallade “system 1”: intuitiv, snabb och omedveten mönsterigenkänning (Multiplikationstabellerna!). Men funkar det lika väl för “system 2”: långsam, logisk och algoritmiskt resonerande? (Liggande stolen!) Kan man uppnå generell intelligens utan långsiktigt och medvetet resonerande?
Inte ens auktoriteter inom djupinlärning som François Chollet, skaparen av det populära ramverket Keras, är övertygad om att djupinlärning kommer att dominera för alla typer av problem. Han är öppen för att nya paradigm kan komma, på samma sätt som djupinlärning ersatte tidigare approacher för tio åren. Han påpekar att de flesta nya tekniker följer en sigmoid-kurva där förbättringstakten är hög i början men avtar efter ett tag. Kanske har vi redan realiserat de allra största vinsterna med djupinlärning?
Och Demis Hassabis, en av världens mest kända AI-forskare som medgrundat AI-labbet DeepMind, påminner om djupinlärning är modellerat just på syncentrum, och kanske funkar bäst för just uppgifter som kräver att analysera snarare än att resonera:
You can think about deep learning as it currently is today as the equivalent in the brain to our sensory cortices: our visual cortext or auditory cortex. But, of course, true intelligence is a lot more than just that, you have to recombine it into higher-level thinking and symbolic reasoning, a lot of the things classical AI tried to deal with in the 80s. We would like [these systems] to build up to this symbolic level of reasoning--maths, language, and logic. So that's a big part of our work.
Just att koppla kunskap till specifika termer (“symboler”) anser vissa vara nödvändigt för att fortsätta utveckla maskinintelligens bortom en viss nivå. Hur kan en modell vara intelligent om den inte vet vad en kanin är, mer att den sett i vilka sammanhang ordet används, och inte vet hur en kanin beter sig?
De som lyfter fram vikten av symbolhantering brukar exemplifiera med de problem som DALL-E och andra bildgenereringsmodeller möter med att hantera den så kallade kompositionalitetsprincipen. De lyckas helt enkelt inte bygga upp en mental bild av en komplex beskrivning, där information existerar i hierarkier. Till exempel har de svårt att hantera objekt med olika färger och former i samma beskrivning. Så här blir “a blue cube on top of a red cube, besides a smaller yellow sphere”:

Dock, en invändning: även en del mänskliga intelligenser har ganska svårt med den typen av kompositionalitet. Barn, eller personer som inte är vana vid abstrakta resonemang, eller till och med personer som inte koncentrerar sig, hade också haft svårt att följa instruktionen till DALL-E. Och om även stora biologiska hjärnor kan prestera dåligt på den här typen av resonemang, är det så konstigt att AI-hjärnor med mycket färre kopplingar presterar sämre idag? Kanske faller det här på plats ju större hjärnorna/modellerna blir?
So sure, point out that large language models suck at reasoning today. I just don’t see how you can be so sure that they’re still going to suck tomorrow. Lemurs sucked for millions of years, then scaled up a bit and took over the world!
(Och: Googles LaMDA verkar rätt bra på sånt här redan idag!)
Finns det något mellanting?
Kanske är inte den viktiga frågan om ifall modellerna hanterar symboler eller inte, utan om reglerna och kunskapen är hårdkodad av människor vs. inlärda av en dator? AlphaGo Zero har till exempel lärt sig spela go helt själv, utan att bygga på mänsklig erfarenhet, och efterföljarna AlphaZero och MuZero har lärt sig spela fler spel utan att ens ha hårdkodade regler. Men alla tre använder ändå en s k Monte Carlo-trädsökning för bedöma bästa framtida drag. De är alltså inte bara baserade på djupinlärning. Kan man tänka sig “neurosymbolisk maskininlärning”, som bygger på djupinlärning men ändå implementerar stöd för symbolhantering och förmåga för logisk slutledning?
Ska man uppnå generell intelligens kan ju sådana tilläggslösningar inte bli alltför domänspecifika. Man måste ju i så fall tro på att de grundläggande mekanismerna funkar för olika sorterss problemlösning, på samma sätt som olika hjärndelar kan ersätta varandra vid till exempel skador (även om en del hjärnstrukturer som sagt är hårdkodade). Här finns redan nu flera idéer. Till exempel diskuteras hur man kan komplettera en standard ML-arkitektur med externt minne för att skapa ett större strukturerat “långtidsminne”, något som kan ses en steg tillbaka mot Metod 1.
Icke-vägledd träning (unsupervised learning) är ett paradigm inom ML som gjort GPT-3 möjligt: modellen försöker generalisera samband själv utan att tränas på data som en människa förberett. Och Som Metas AI-chefsforskare Yann LeCun skriver, kanske måste framtidens modeller ta det ett steg längre och göra som människor: lära sig själv genom att utforska världen.

Han ser ett behov av nya koncept som låter maskiner förstå hierarkiska strukturer bättre, analysera orsakssamband, och förstå osäkerhet. Men han verkar samtidigt se den matematiska optimeringsmetod (gradient descent) som ligger bakom modern maskininlärning som basen även i framtiden. Så i hans vision lär sig maskiner även framöver genom att söka igenom ett enormt utfallsrum av statistiska korrelationer genom smarta matematiska algoritmer.
Sammanfattningsvis
Ja, det är svårt att förstå hur miljarder vikter tillsammans kan representera en förmåga att omvandla en fråga till ett svar. Men det är också svårt att förstå hur miljarder neuroner kan lyckas med samma sak. Så låt oss vara ödmjuk i att vi inte vet riktigt hur intelligens uppstår eller inte uppstår.
Personligen tycker jag att det har varit väldigt fascinerande att följa modellerna blir smartare bara genom att bli större. Människor har i årtionden försökt skapa smarta chatbotar genom att manuellt ge dem tiotals miljoner regler. Men när vi istället tog tiotals miljoner hemsidor och lät tusentals datorer själva hitta samband under lång tid, då lossnade det. Det är svårt att inte se vissa — i alla fall ytliga — paralleller till evolutionen, som genom en “osynlig hand” av ändlösa iterationer gav oss en högfungerande hjärna.
Och som Richard Dawkins brukar säga, evolutionen är verkligen “the greatest show on earth”. Ibland är slutresultaten magiska, även om det inte finns någon trollkarl utan bara massa små, iterativa steg. Kanske gäller det samma för maskininlärning.
Personligen är jag inne på samma linje som Meta-chefen: maskininlärning baserat på automatiserad bearbetning och matematisk optimering av stora mängder data är nog den mest framkomliga vägen mot generell intelligens. Däremot ska det bli spännande att se om modellerna fortsätter prestera bättre om man kopplar på symbolhantering för olika syften, såsom man gjort i AlphaZero och MuZero.
Det här var allt för idag. God fortsättning på julen!
Om du har vänner som du tror skulle gilla nyhetsbrevet, vidarebefordra det till dem eller tipsa dem om att prenumerera för att få framtida utskick (det är helt gratis!).
—Jacob